
 搜索
搜索  数字报
数字报  深圳号
深圳号  投诉举报
投诉举报  读特新闻记者 严偲偲
读特新闻记者 严偲偲
明确农作物实际产量与潜在产量之间的产量差距,对于提升农业生产力、保障国家粮食安全具有重要意义。然而,我国南方地区的单双季水稻种植模式交错混杂,在单双季水稻混合种植的农业系统(下称“混作系统”)中,传统方法难以有效识别不同稻作类型的产量构成,导致对水稻增产潜力评估存在较高不确定性。
近日,中国科学院深圳先进技术研究院数字所研究员陈劲松、助理研究员王靖雯等在行业期刊《农业计算机与电子》上发表最新研究。团队提出了一种知识引导的机器学习(KIML)建模框架,突破了当前混作系统中单、双季稻产量标签缺失对传统AI建模的限制,在弱样本条件下实现了对南方单、双季稻混作区产量构成的精准识别与增产潜力的量化评估。
当前,混作系统中可用的产量样本数据通常仅包含种植区域内单、双季稻的混合均值,难以支撑AI模型学习并识别不同稻作类型的产量构成。针对这一问题,研究人员通过引入遥感技术提取的作物种植强度数据,并将其转化为结构性知识约束嵌入AI模型训练过程中,引导AI模型在学习过程中自动完成对混合产量构成的合理解耦,从而实现混作系统内多类型水稻产量的定量识别。
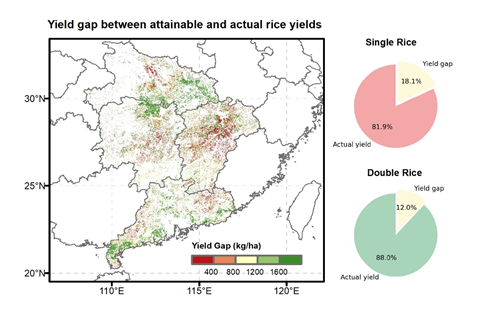
南方混作区单双季稻增产潜力空间分布图。
验证结果表明,KIML模型对于南方混作区单、双季稻的产量估算精度分别达到85.8%和89.8%,有效纠正了传统机器学习模型对单季稻产量的低估与双季稻产量的高估偏差,进而显著提升了后续增产潜力评估的可靠性,估算精度提升约12.1%。结果显示,在当前种植模式下,中国南方混作区(湖南、湖北、江西、广东)水稻的实际产量水平与可获得潜在产量之间仍存在约1235万吨(13.9%)的增产空间,其中单季稻与双季稻分别贡献46.2%和53.8%。
传统的机器学习方法由于难以准确识别单双季水稻产量的构成,对水稻总体增产潜力的估算存在显著高估。“提升混作区水稻增产潜力的估算精度对于准确把握粮食安全形势具有重要意义。我们利用KIML模型学习解析单双季水稻的混合平均产量信息,实现了对单双季水稻的增产潜力的精准估算。”陈劲松表示,该研究有望为我国南方地区粮食主产区科学制定种植策略、优化资源配置、提升粮食产量提供坚实的数据支撑。
编辑 秦涵 审读 郭建华 二审 周梦璇 三审 万晖
 报料
报料 



 读特热榜
读特热榜  IN视频
IN视频 




 鹏友圈
鹏友圈 






 iPhone客户端
iPhone客户端  安卓客户端
安卓客户端 
