
 搜索
搜索  数字报
数字报  深圳号
深圳号  投诉举报
投诉举报  读特新闻记者 袁斯茹
读特新闻记者 袁斯茹
4月25日,Create 2025百度AI开发者大会在武汉举办。百度创始人李彦宏发布了文心大模型4.5 Turbo、深度思考模型X1 Turbo两大模型,以及多款AI应用。百度首席技术官王海峰现场详细解读了背后的技术。

王海峰在现场
两大模型连发!核心技术详解
王海峰介绍,文心大模型4.5是多模态基础大模型,文心4.5 Turbo源自于此,效果更好、成本更低;基于文心4.5 Turbo,文心X1升级到X1 Turbo,性能提升的同时,具备更先进的思维链,问答、创作、逻辑推理、工具调用和多模态能力进一步增强。
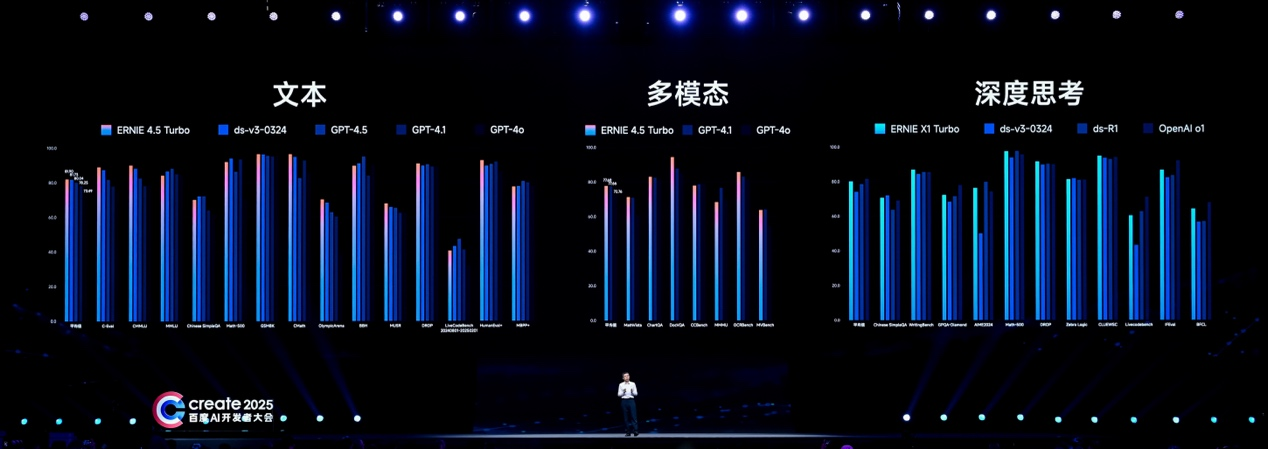
“在多个基准测试集中,文心4.5 Turbo和X1 Turbo跟DeepSeeK与GPT模型相比,效果在伯仲之间。”王海峰说。
大会现场,王海峰从基础模型、后训练、深度思考和数据等方面解读了两大模型的关键技术。
文心4.5和4.5 Turbo都是多模态大模型,实现了文本、图像和视频的混合训练。针对不同模态数据在结构、规模、知识密度上的差异,通过多模态异构专家建模、自适应分辨率视觉编码、时空重排列的三维旋转位置编码、自适应模态感知损失计算等技术,大幅提升跨模态学习效率和多模态融合效果,学习效率提高近2倍,多模态理解效果提升超过30%。
后训练方面,百度研制了自反馈增强的技术框架,基于大模型自身的生成和评估反馈能力,实现了“训练-生成-反馈-增强”的模型迭代闭环,不仅解决了大模型对齐过程中,数据生产难度大、成本高、速度慢等问题,而且显著降低了模型幻觉,模型理解和处理复杂任务的能力大幅提升。
在训练阶段,研制了融合偏好学习的强化学习技术,通过多元统一奖励机制,提升了对结果质量判别的准确率,通过离线偏好学习和在线强化学习统一优化,进一步提升了数据利用效率和训练稳定性,并增强了模型对高质量结果的感知。
深度思考方面,突破了仅基于思维链优化的范式,在思考路径中结合工具调用,构建了融合思考和行动的复合思维链,模型解决问题能力得到显著提升。数据方面,打造了“数据挖掘与合成 - 数据分析与评估 - 模型能力反馈”的数据建设闭环,为模型训练源源不断地生产知识密度高、类型多样、领域覆盖广的大规模数据。
人人都可以成为程序员
基于文心大模型的语言和代码能力,百度研制了代码智能体和智能代码助手——文心快码。
代码智能体,基于智能体的理解、规划、反思,以及工具调用能力,用自然语言对话,即可实现应用的自动开发,并支持多轮交互,迭代优化代码质量,实现了无代码编程,让人人都可以成为程序员。
目前,文心快码向全社会开放,累计服务760万开发者。
此外,文心大模型的能力拓展和效率提升,得益于飞桨文心的联合优化。目前,飞桨文心开发者数量已超过2185万,服务超过67万家企业,创建的模型达到110万。

首个“非遗武术大模型”发布
随着人工智能技术加速进步,大模型在千行百业的应用也越来越深入。
在非遗武术传承领域,百度与上海体育大学武术学院、中国武术博物馆联合发布“非遗武术-百度文心大模型”,基于文心大模型,融合上海体育大学武术学院、中国武术博物馆的专业积淀,将武术技法与算法结合,通过3D动作建模、AI动态纠错等技术,将非遗武术技术动作以数字化的形式保存和记录下来。
活动最后,第十二届百度奖学金颁奖典礼在现场举办。作为国内外AI领域资助金额与含金量最高的学术奖学金之一,百度奖学金自2013年设立以来,已累计发放超千万元资金。王海峰为来自全球顶尖高校的10位获奖选手颁发奖学金,每人20万元。
(本文图片来自百度)
编辑 张克 审读 张蕾 二审 关越 三审 万晖
 报料
报料 



 读特热榜
读特热榜  IN视频
IN视频 




 鹏友圈
鹏友圈 






 iPhone客户端
iPhone客户端  安卓客户端
安卓客户端 
