
 搜索
搜索  数字报
数字报  深圳号
深圳号  投诉举报
投诉举报 过去的2020年,人工智能研究组织OpenAI打造的1750亿参数文本生成器GPT-3火爆全球。用它撰写的博客文章成功欺骗了很多人类读者。不少业内人士认为,GPT-3对AI行业具有颠覆力量。可以看到,自然语言处理的神经网络规模越来越大,功能也越来越丰富。
当地时间2021年1月5日,OpenAI又放出大招,在官方博客公布最新人工智能神经网络“DALL·E”。OpenAI称其可以通过自然语言文本直接生成对应图像,意味着“通过语言文字操纵视觉概念现在已经触手可及。”
OpenAI 的这项最新成果引来不少AI大牛的关注。Coursera 创始人、斯坦福大学教授吴恩达就在社交媒体表示祝贺,还选出一则他认为“非常酷”的OpenAI文字生成图像示例——由AI生成的蓝色衬衫搭配黑色长裤图像。

吴恩达对OpenAI表示祝贺。
据OpenAI介绍,DALL·E基于120亿参数版本的GPT-3模型,使用文本-图像对的数据集,能够通过文字描述生成图像。OpenAI研究人员发现,DALL·E有一系列不同功能,例如创建动物或物体的拟人化版本、以合理的方式组合不相关的概念、文字渲染以及对已有图像进行变换等等。
“DALL·E”的名字来自艺术家萨尔瓦多·达利(Salvador Dali )和皮克斯的机器人WALL-E。

从文本“穿着芭蕾舞裙的萝卜宝宝在遛狗”生成的图像。
在他们给出的第一批示例里,文本“穿着芭蕾舞裙的萝卜宝宝在遛狗”被拟人化地呈现在图像上。类似的例子还有“一只模仿乌龟的长颈鹿”、“一杯被恋爱冲昏头脑的波霸奶茶”等。从这些案例中,研究人员发现,DALL·E能够将人类活动和衣物,甚至情绪迁移到动物和无生命物体上。
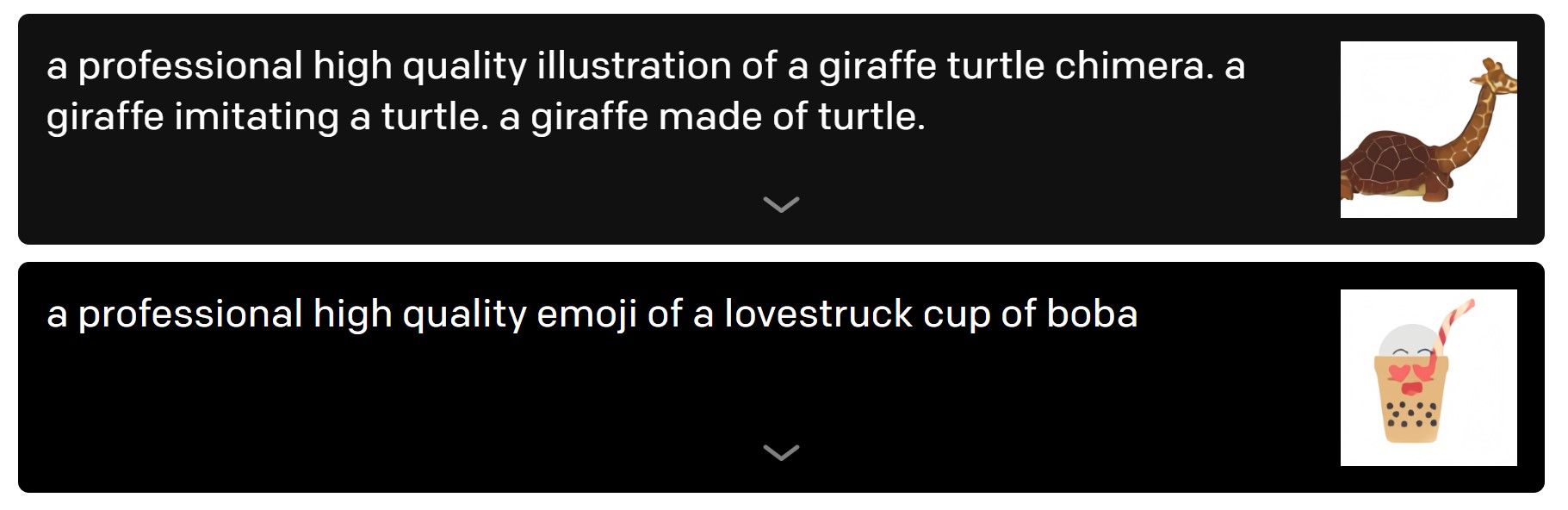
由文字生成的长颈鹿和奶茶图像
DALL·E的第二个功能是以合理的方式组合不相关的概念。譬如,“一把牛油果形状的扶手椅”,这一天马行空的描述,也被DALL·E以看似合理的方式呈现在图像中。

从文本“一把牛油果形状的扶手椅”生成的图像。
第三大功能更为实用——文字渲染。研究人员发现,DALL·E能够在图像中呈现文字,并使文字的字体风格适应周围环境。不过,这类功能只能在少量字符下使用,输入的字数越多,成功率越低。

从文本“一家门前写有‘OPENAI’的商店”生成的图像。
除了以上这些功能,DALL·E还可以对动物照片进行多种图像变换。下图就是它为同一只(不存在的)猫画的多幅草图。

从文本“上面一排一样的猫,下面是它们的草图” 生成的图像。
2020年6月,Open AI发布大型生成式语言模型GPT-3,全称Generative Pre-training Transformer-3。通过对不同的书面材料集与长篇连载文本的预训练,GPT-3获取了大量知识,有 1750 亿参数,远超此前类似语言模型,参数量较2019年2月发布的GPT-2高两个数量级。
自发布之日起,GPT-3因强大功能和令人惊叹的测试结果备受关注。它可以实现的功能包括:输入一句自然语言后,模型自动完成编程;对模型描述一种病症,它可以指出是什么疾病并开出药方;甚至询问一些关于人生信仰的问题,模型也可以做出回答。
从专注文本任务的GPT-3到最新的DALL·E,OpenAI表示:GPT-3证明了语言可以指导大型神经网络执行各种文本生成任务;而Image GPT表明,同样类型的神经网络也可以用来生成高保真的图像。“这些发现说明,通过语言文字操纵视觉概念现在已经触手可及。”
OpenAI成立于2015年,是一家以研发通用人工智能为目标的公司。公司官网称,其使命是确保通用人工智能(AGI),即一种高度自主且在大多数具有经济价值的工作上超越人类的系统,将为全人类带来福祉。
编辑 曹亮
 报料
报料 



 读特热榜
读特热榜  IN视频
IN视频 




 鹏友圈
鹏友圈 






 iPhone客户端
iPhone客户端  安卓客户端
安卓客户端 
