
 搜索
搜索  数字报
数字报  深圳号
深圳号  投诉举报
投诉举报  读特客户端综合
读特客户端综合3月30日,OpenAI在官网上公开了其最新的研究成果——“Voice Engine”。这项技术可通过简短的15秒音频样本和文本输入,生成与原始说话者极为相似的自然语音。

在公告中,OpenAI给出了Voice Engine的一些早期应用场景。如通过自然、富有情感的声音辅助儿童阅读、翻译视频和播客等内容、改善偏远地区的社区服务、帮助患有突发性或退化性言语病症的患者恢复声音等。
针对上述应用场景,OpenAI也分别给出了和少数“值得信赖”的合作伙伴共同完成的技术案例。儿童教育公司Age of Learning使用GPT-4与Voice Engine与学生进行个性化的交流;人工智能替代通信应用程序Livox通过使用语音引擎,为残疾人提供跨多种语言的自然声音;此前靠“Taylor Swift说中文”等视频爆火的Heygen也有使用Voice Engine。
OpenAI称,Voice Engine技术于2022年底开始开发,目前已经为文本转语音API和ChatGPT的朗读功能提供预设语音。至于模型训练的数据来源问题,OpenAI语音引擎产品团队成员杰夫·哈里斯 (Jeff Harris)在接受媒体采访时表示,该模型是根据“许可数据和公开数据的组合”进行训练的。
尽管此前已经为“Voice Engine”申请了商标,但是对于未来是否要大规模部署这项技术,OpenAI仍保持保守态度。2024年2月,美国曾发布了少数公司利用总统的人工智能语音来影响选民投票的事件,类似的潜在风险也是OpenAI选择先小范围应用Voice Engine的一大原因。
公告中显示,由于合成语音存在被滥用的可能性,OpenAI希望就合成声音的负责任部署以及社会如何适应这些新功能展开讨论,根据讨论和小规模测试的结果,OpenAI将会对是否大规模部署这项技术做出决定。
OpenAI在人工智能安全方面曾早早做出准备。2023年10月,OpenAI 宣布成立“准备团队”(Preparedness team),旨在监测和评估前沿模型的技术和风险;随后于2023年12月,OpenAI进一步公布了“准备框架”(Preparedness Framework),介绍了围绕OpenAI“追踪、评估、预测和防范灾难性风险”所制定的一系列机制。
对于Voice Engine,OpenAI表示正在探索对合成声音加水印或添加控制措施的方法,以防止人们使用带有政治家或其他知名人物声音的技术。
另外,值得一提的是,去年爆火的视频翻译软件HeyGen,采用的语音引擎也正是Voice Engine。

网络视频截图
2023年10月,不少郭德纲说英文相声、赵本山伦敦腔接受采访的视频开始在互联网风靡,这背后的核心技术来自于一款AI视频工具HeyGen。其在国内的主体是一家深圳的AI公司——诗云科技,取自刘慈欣的小说《诗云》,主营AIGC,成立时间为2020年11月。
但天眼查显示,诗云科技目前已处于注销状态。
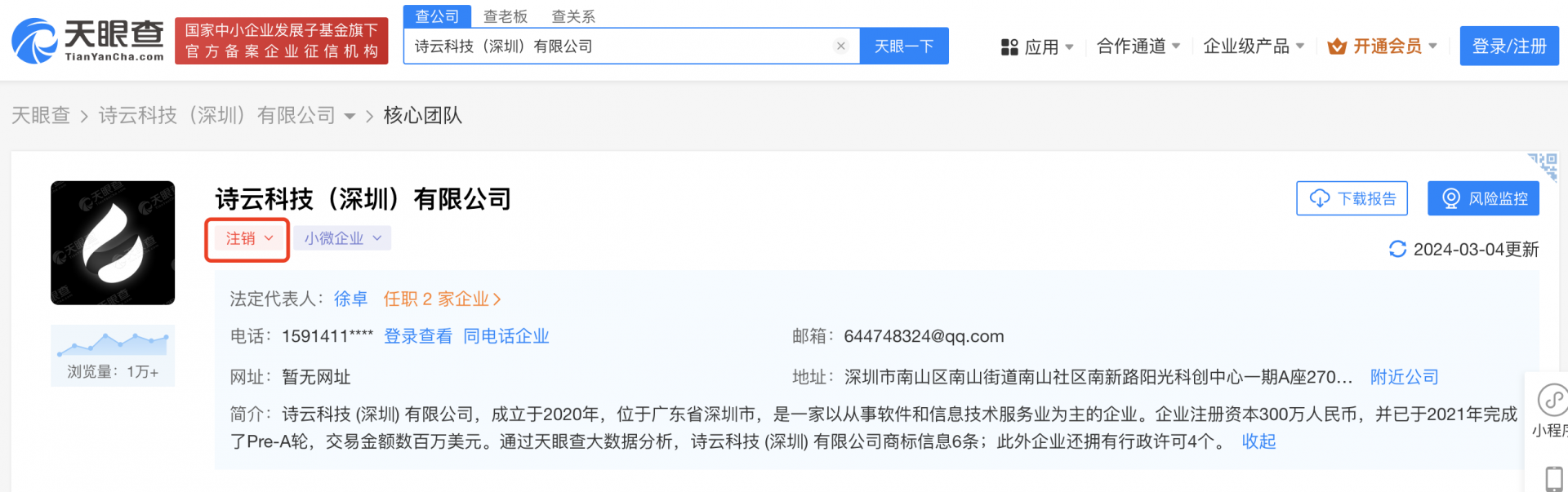
天眼查截图
(综合来源:界面新闻、科创板日报、天眼查等)
编辑 张克 审读 伊诺 二审 关越 三审 詹婉容
 报料
报料 



 读特热榜
读特热榜  IN视频
IN视频 


 鹏友圈
鹏友圈 






 iPhone客户端
iPhone客户端  安卓客户端
安卓客户端 



